
So much of getting generative AI to do something involves endless fidgeting with prompts, testing the ever expanding list of LLMs, and figuring out what “good” even looks like. As someone who did traditional ML and deep learning for many years, this sounds very much like the undifferentiated work from traditional ML: should I use a random forest or binary classification? Should I use 40 trees or 60? Tree depth?
The Traditional ML space used automation and techniques like Bayesian optimization of hyperparameters, i.e., broadly termed AutoML, as a means to remove this undifferentiated and tedious work. While AutoML is not without limitations (overfitting being the primary) it has become an effective way to empower teams with limited DS/ML expertise to perform simple data science and a surprisingly effective way for experts to get to a useful starting point. In fact, none of the AI-ML Platforms would be complete without AutoML capabilities.
The similarity of the challenges encountered in traditional model building and GenAI “app” building begs the question: can we use AutoML techniques to remove the undifferentiated work in building GenAI?
That is the question we set out to build with our GenAI Workbench and its been exciting to see the effectiveness of these techniques. So, in this post, I’m going to draw the parallels between AutoML for these disparate problems, highlight what’s solved, what remains open and where we can go from here.
First, a quick primer on AutoML for Traditional (predictive) ML:
AutoML seeks to take an input dataset {X, y} and seeks to produce the best function “f” such that f(X) → y. It does so by exploring the space of models (f-s), their hyperparameters and different transformations of X.
Here are the steps involved and the output:
- Select candidate models
- Select model hyperparameter variations
- Select feature engineering strategies
- For all(*) combinations of above, train models on the training split of the dataset
- Evaluate models on the test split dataset (or via cross validation)
- Select the model with the best performance metric depending on the use case
Output from AutoML typically looks like this:
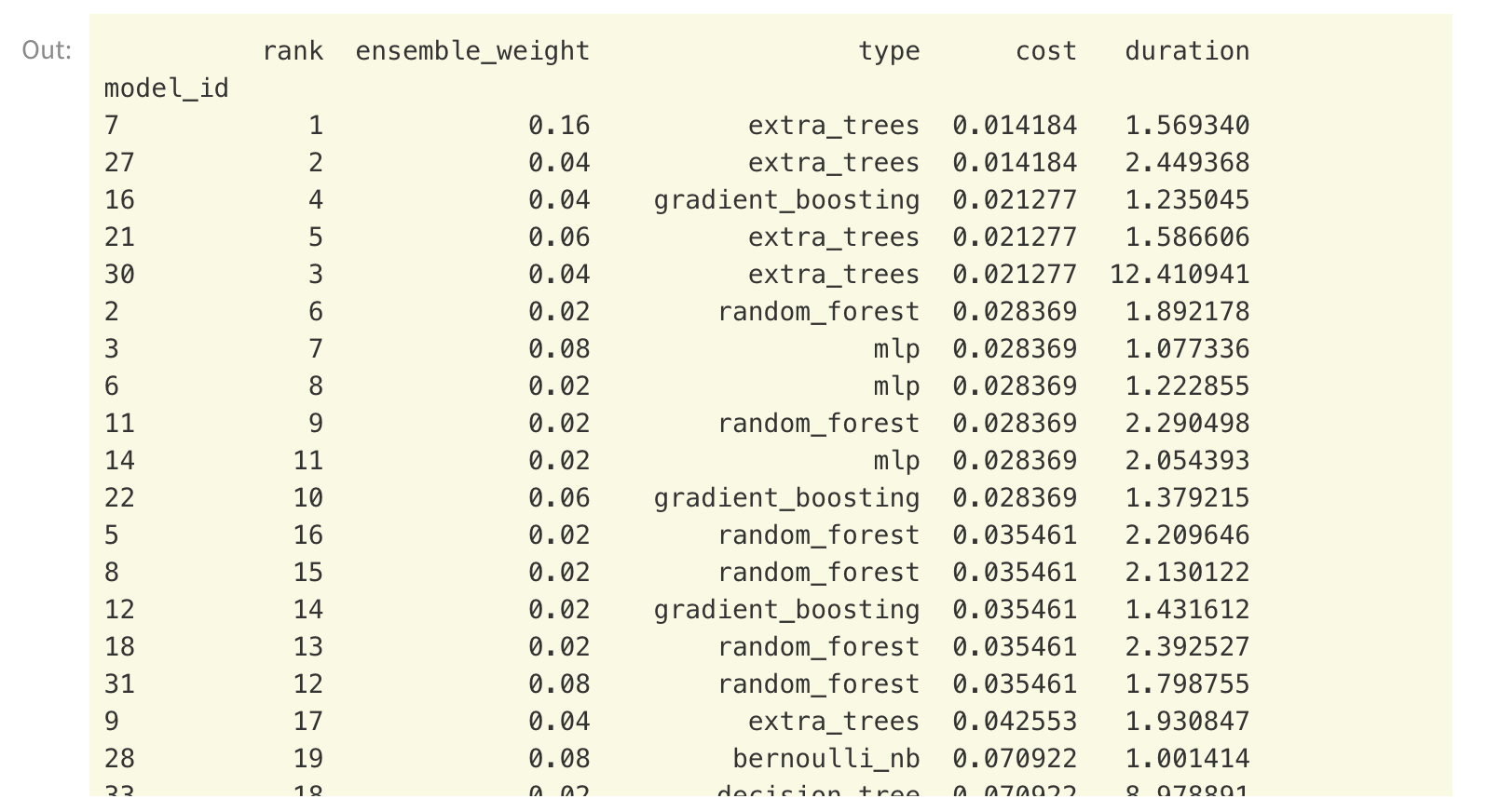
Now on to GenAI, how can we use the same AutoML techniques for GenAI?
AutoML for GenAI has the same philosophy as for traditional ML with a few tweaks as shown in the table below. For example, since LLMs are typically pre-trained, this removes the need to perform model training. In addition, instead of varying hyperparameters, we vary input parameters like prompt, temperature, and chunking.
|
AutoML for Traditional ML |
AutoML for Generative AI |
|
|
1 |
Select candidate models |
Select LLMs |
|
2 |
Select model hyperparameter variations |
Select input parameter variations, primarily prompts |
|
3 |
Select feature engineering strategies |
Not required |
|
4 |
For all combinations of above, train models on the training split of the dataset |
Not required |
|
5 |
Evaluate models on the test split dataset (or via cross validation) |
Not well defined |
|
6 |
Select the model with the best performance metric depending on the use case |
Not well defined |
Digging deeper, the challenges applying AutoML to Generative AI are three fold:
- Experimenting with prompt variations: While hyperparameters are usually numeric (e.g., “C” value) or belong to a small number of categories (e.g., gradient descent algorithm), the universe of prompts is much more open-ended and complex: you can view it as a very high dimensional vector (as some work does.) As a result, techniques like Bayesian optimization are much more challenging to apply effectively.
- Datasets: Often, when beginning a GenAI project, the train/test dataset is hard to build. Gen AI may represent a new type of task where training data has not been captured or even available, e.g., when building a bot to turn engineering notes into blogs, there may be no data about past engineering notes.
- Evaluation & metrics: While computing accuracy in traditional ML is very formulaic, evaluating LLM results today is extremely ad-hoc, with many teams resorting to “vibe cheks.” This challenge is further complicated by the fact that it can be hard to describe what good may look like unless you see some examples (“the language is too flowery”, “this is too long.”)
Although these challenges make AutoML for GenAI different from AutoML for traditional ML, we have found through that these hurdles are not unsurmountable, here are some of the techniques we have been using in the Workbench:
- Autoprompting and AI-powered prompt refinement: New and better ways to prompt LLMs are constantly being developed (e.g., Chain-of-Thought, Reason-And-Act etc.) In addition, meta-prompting work has begun to show promise for helping craft effective prompts. Autoprompting combined with meta-prompting is now good enough to generate prompts automatically. Automatically generated prompts are not perfect, but in most cases, 100% better than what a beginner would write.
- Evaluation: LLM evaluation is hard and an active research problem. But the basics are fairly clear: use automation to perform a rough ranking of results and select a small number of results to perform human comparative evaluation to compute ELO scores to finalize the ranking. In our experience, with tens of comparisons, you can arrive at a fairly robust ranking of model-prompt combinations.
- Datasets: And finally, for datasets, to get to someone decent, you don’t need 100s, you need tens. That order of magnitude makes the problem much more tractable.
With these techniques, we can get from User Task description to a high-quality app in 23 minutes. That’s pretty darn great. Again, the goal of AutoML is not getting to the SOTA result, it is to get to a result that is “good enough” and iterate from there.
I’m excited about the promise of AutoML for Generative AI and as a means to get to useful Generative AI faster. If you’ve done these explorations yourself, would love to hear your experiences and collaborate with you. And if you want to see for yourself how well this can work in real-life, give it a spin at app.verta.ai.
Subscribe To Our Blog
Get the latest from Verta delivered directly to you email.


.png)