Last April, Git celebrated its 15 year anniversary! It has by now become the defacto standard for versioning your code. It made many things much easier to do than its competitors and successfully created a vibrant and still growing ecosystem. However, the field of machine learning is still figuring out how to leverage the benefits it brings. I have researched why Git won the battle, its shortcomings, how the ecosystem has improved to counter them, and the key takeaways we need for machine learning. At this historical moment, I wanted to share this journey with you.
Why does Git rock?At first glance, Git looks like it's just solving the problem of versioning source code and keep track of changes through time. Although that's true, it wouldn't be much of a difference from other tools in this space. SVN was released in 2000 and Perforce in 1995, but many of today’s developers have never used or even heard of them. Both solved the problem of tracking changes in source code in their way. So why is Git different?
Git focuses on collaboration. Its original purpose was to improve developer experience in the Linux kernel, an inherently collaborative project. From a Git repository, you can quickly create a branch, do several commits and merge back into master. The ability to integrate several small changes quickly provided a lot of benefits and was a game-changer.
With Git, you don't need to accumulate big chunks of changes because the process of integrating back is expensive. You can have a single, big commit if you want to, but be prepared to handle conflicts and lose track of your work. Small changes facilitate state checkpoints, code reviews, and incremental development. If something is not working correctly, you can quickly narrow down to why and revert to that state without losing other functionality (git bisect is great!). Every commit tells you exactly what changed and how. Small commits also help pick changes on top of the others, since it becomes much easier to apply a commit to a different base.
Git also makes teams more productive. If your organization is using the Git workflow, you can create several short-lived branches for each feature without worrying about merging. Git gives you a smart merge mechanism that either automatically converges multiple code changes or at least tells you on which conflicts you need to focus. For anyone who has worked with a monolithic source code manager before, this is amazing. Instead of collecting changes to send once as a big block, hoping that nobody changed any file that you did (and that the reviewer is in a good mood for a slow review), you can send as many small, incremental changes as you see fit.
With these gains, using source version control became less burdensome. Add the feature of knowing who changed a file, when the change happened and how to get back to it, and you have an auditable system that doesn't get in the way of your team shipping features. This combination allowed "Anything as Code" innovations to flourish. Infrastructure as code, configuration as code, basically anything that you can save into a file can also leverage Git's benefits. It integrates with the developer workflow more transparently, while also concentrating any process into a single path.
Despite all its benefits, Git isn't a silver bullet. The three main unsolved pains with pure Git are:
- managing changes and collaboration so that versions don't become a wild west;
- leveraging meaning about the content of files to provide specialized development tools; and
- connecting a code version to its resulting artifacts.
These are important for developer experience, so the industry had to find solutions.
Going beyond Git
Changes to a Git repository "just happen." If you have permission to push to it, your changes can be available without anyone's interference. This flexibility places a burden on organizations and individuals to figure out processes to make such changes. GitHub solved this problem very well.
Github's pull requests solve the base problem of managing changes. You can make a change and, instead of directly pushing it, you can request a pull. Someone will review it, maybe you'll do some small fixes, and it will get merged. But did you know Git by itself supports pull requests? I bet you didn't, because the flow is not very friendly to most devs. Making a tool pleasant to use is as valuable as providing the mechanism itself. GitHub gives us a great way to see changes, review, and analyze them. And it also provides integrations throughout the process. You can run CI to ensure the code is right, or you can support owners to require specific people to approve a change. It gives you a way to enforce processes on top of your Git flow.
Another thing that GitHub does well is helping you navigate the repository. When you have code in your local machine, you can always use "grep" or the search in your IDE to find something. Your IDE also helps you navigate through references in your code as long as it understands the file type. This navigation enables you to find what you want quickly, and it's one of the pillars of a good IDE. GitHub recently enabled this understanding of files content to their web app, learning from IDEs. I lost count of how many times I've used that navigation in GitHub to see a change without having to manipulate any file locally.
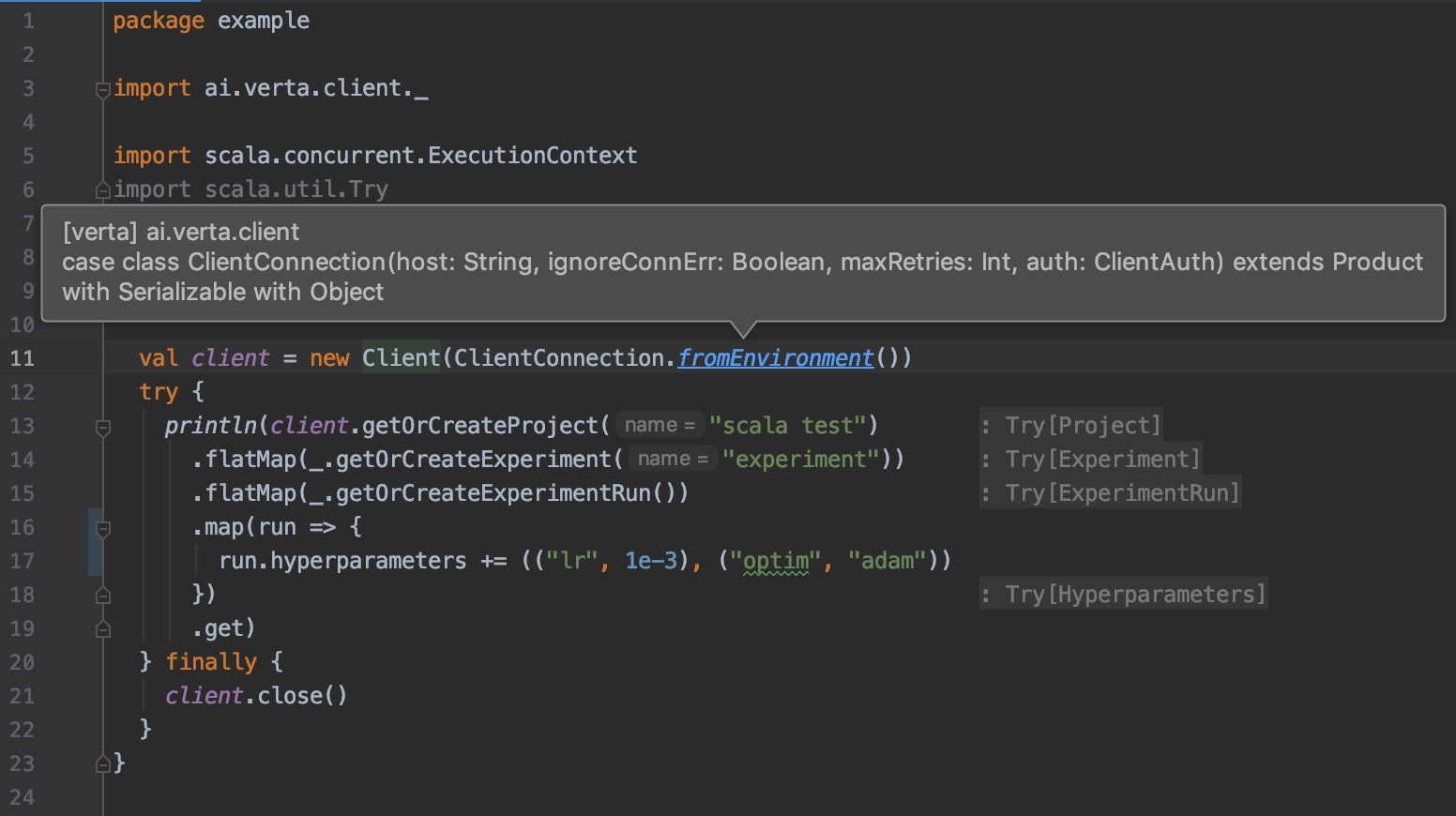
When you give semantic meaning to files, they become more than just lines of text. They become a Java class in a specific package, or an interface that you can use, or a vast number of other options. If your tools lack understanding what the file type means and what you want to do with it, it doesn't give you many more features than a bare text editor. Ask any Kubernetes user about their experience with YAML if you doubt. As projects become more complex and you need to deal with different file types, this becomes a more critical issue.
That is a big drawback of Git: it doesn't care about file types. A file is a file for Git. If it's text, you get some generic text features to identify lines of code around it. Add space to a line of code, and it becomes an entirely new line. If you're not dealing with text, you're out of luck. That's why IDEs expand on top of Git and integrate into it. Git is a tool that solves some problems, but not all. You are on your own to deal with the many file types you need.
Another problem is the relationship between code and their artifacts. This connection is surprisingly underdeveloped today. For example, if you go to Docker Hub, the source code used to build an image is not explicitly connected. Most teams have developed some conventions to solve this problem. They might add some metadata with the commit, or a tag matching the tag in the repository, or some documentation linking to the original code. We also practice such conventions internally at Verta, and it's incredibly helpful to tell precisely from where an image came. I have talked with many teams, and all of them work around the tools they have, instead of having tools help them solve this problem. The artifacts don't have to be binaries, but even metrics such as code coverage might be necessary for the development process while not being fully integrated. The more artifacts you have as part of your development process, the harder it becomes to manage them via ad-hoc systems.
What can we learn for ML development?
Machine learning models are more complex to build than software. The engineer defines the problem in terms of the requirements (dataset) with some potential paths (hyperparameters). That information is then consumed by an algorithm (code + environment) that will not compute the solution directly but will instead create an artifact that computes the answer. As those familiar with the idea of Software 2.0 will recognize, this is essentially building the model.
This process involves all the issues we discussed before. It's an inherently collaborative process, where different people focus on different areas, such as modeling and feature engineering, to achieve a single goal. Every unique change is hard to debug and takes many iterations to get right, so you want to make sure everyone can move fast and can work on the latest results. It also involves many interconnected types of data that require specialized reasoning and relationship understanding. It needs to understand that Alice created a dataset that was processed by Bob and consumed by Charlie to create a new model. On every step, there are configurations, code, and environment that need to be tracked and versioned, plus metrics, metadata and artifacts produced.
Focus on developer experience
Solving this is not an easy task. As teams get more sophisticated, we need to provide a more consistent view of the state of versions all through the system by design, not as an afterthought. From the most valuable characteristics that we identified before, this boils down to:
- Providing a Git-like versioning system with similar guarantees,
- With a GitHub-like developer experience and discoverability,
- Integrating file types with interpreted meaning to give an IDE-like feel,
- And connecting to the artifacts and metrics resulting from the computation.
At Verta, we took this challenge to heart. The obvious solution was to leverage Git directly like other groups trying to version ML have tried. But we decided to take a step back and think of the whole experience. The meaning of a file type is essential for the user experience. We know that from IDEs. Saving monolithic JSON/YAML-like files into a filesystem and parsing it in your mind is not the way to go. The model ingredients have meaning, and we should leverage that, not throw them away!
API-first approach to versioning
We took a first-principle approach and developed real versioning for ML via ModelDB 2.0, which is open-source for anyone to use. The original ModelDB originated the idea of tracking models, artifacts and metrics, and collaborating in model development. We decided to step it up for the new version and expand the versioning story to have all benefits of Git.
from verta import Client
from verta.environment import Python
# Get the master for the repository
client = Client("http://localhost:3000")
repo = client.get_or_create_repository("My repo")
master = repo.get_commit(branch="master")
# Create a branch and save
env = master.new_branch("environment")
py = Python(
requirements=["verta"],
constraints=Python.read_pip_environment()
)
env.update("environments/python", py)
env.save("Adding local python environment")
# Merge and see commits
master.merge(env)
for commit in master.log():
print(commit)
We took an API-first approach to files in ModelDB, which enables us to provide both clients and a Git-like CLI. You can perform all the usual operations like branches, adding or removing files, commits, and merges from the comfort of your notebook. Unsurprisingly, we have found ML folks are more comfortable with Python and Scala than with shell scripts. But you can also use the CLI to translate back and forth between the semantically rich world of ModelDB and the simple text files for your filesystem.
Integrated development experience
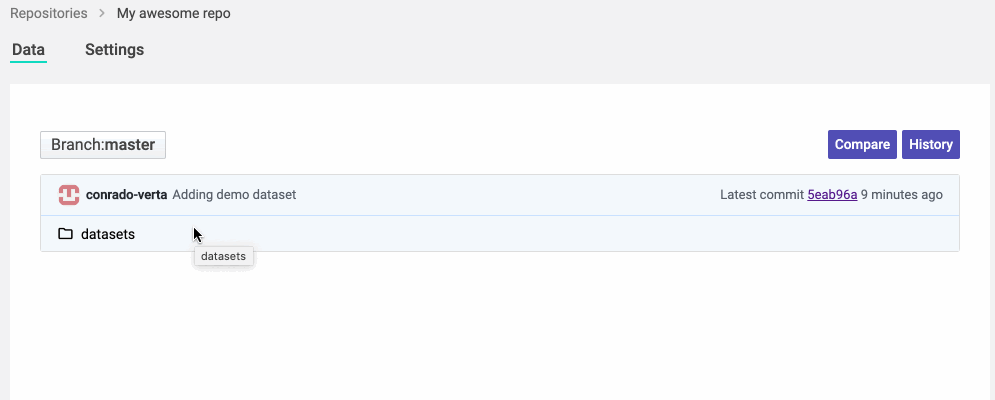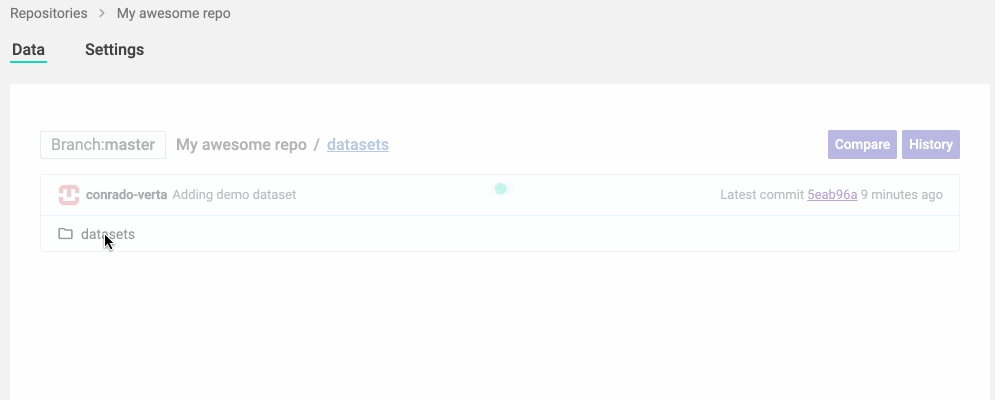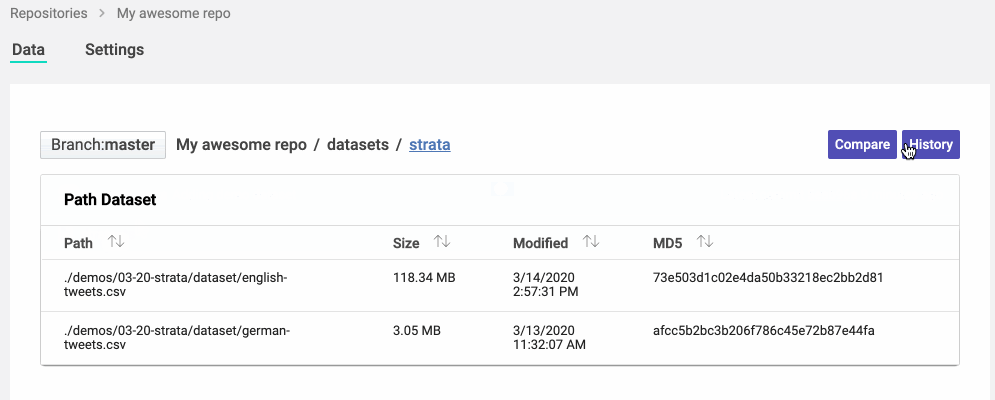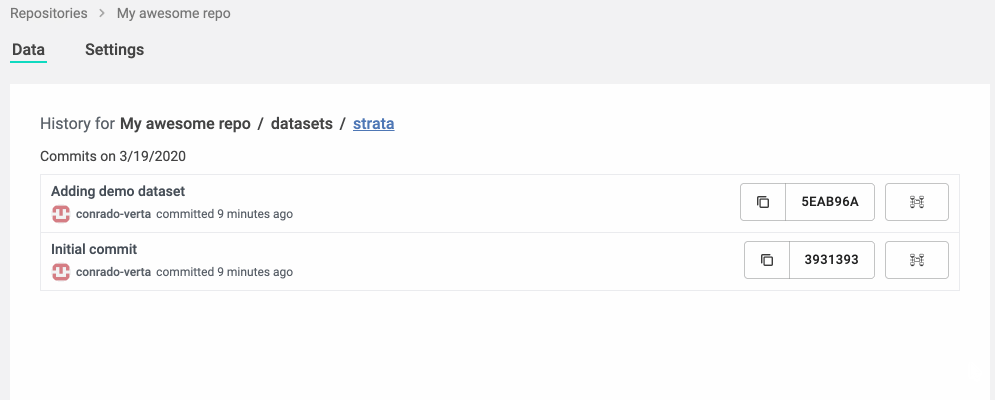
We are also building a fantastic web experience for navigating ML repositories. It took a decade for Git providers to support Java navigation in their repositories, which already existed in IDEs for a decade before. Instead of waiting for your Git provider to understand ML files, we went ahead and built the IDE and visualization for those files and repositories. You can navigate through folders and files, or search for what you want.
You can also analyze the files and changes using visualizations dedicated to the type of data you're seeing. You shouldn't have to read a JSON to see which files are in a dataset; you should have a view that you can understand. Leveraging the knowledge of the type also allows us to do many smarter operations, such as handling merges for datasets differently from merges in environment specifications.
Versioning integrated with tracking
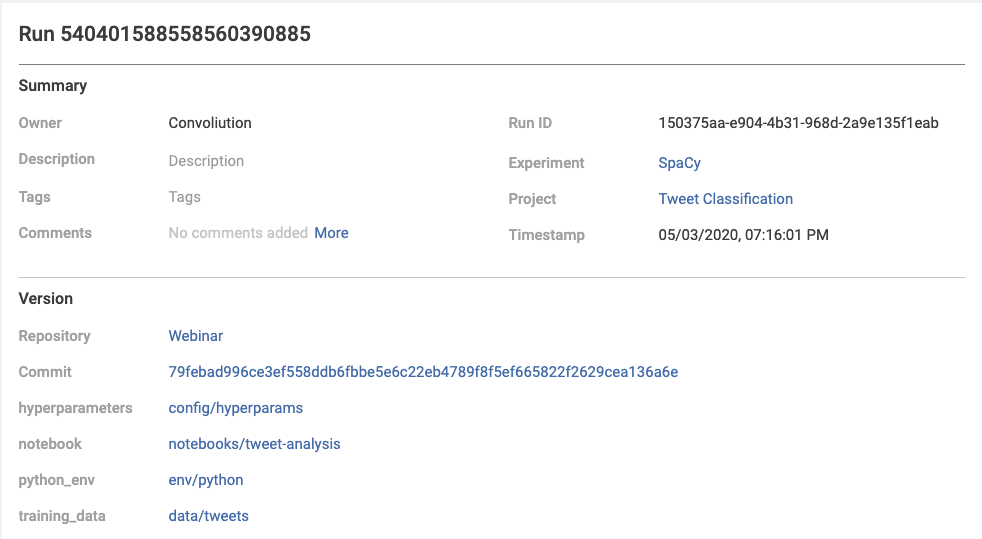
Lastly, every model you build can be tracked precisely to the commit from which it came. This commit can integrate multiple sources of information and covers all ingredients for the model. Instead of being an afterthought, the connection between artifacts and their components is built-in from the start. You can navigate back and forth through your versions and resulting models, search for precisely what you want, and rest assured that you can always go back to your desired state. Versioning expands the information you can access from your tracked models and facilitates analysis of your models.
What does this mean for me?
We made ModelDB 2.0 open and free, both as in beer and in speech, because it is the right thing to do. People deserve ML tools that make their lives easier, not harder. You can simply pick one of the multiple ways we provide for running ModelDB and give it a spin!
We have built ModelDB with the help of the community, and we love to hear feedback and interact with our users. Feel free to reach out in Slack or GitHub issues, or attend one of our webinars. I want to make sure your voice is heard.
What we shared in this post is just the beginning, and there's still a lot more to do. We're thrilled to continue to work with the community to leverage years of know-how from software engineering to machine learning. Versioning and good developer experience is the cornerstone of modern software engineering. Now it shall be for machine learning too.
Subscribe To Our Blog
Get the latest from Verta delivered directly to you email.


.png)