
The Verta Model Catalog is here
I’m proud to share that last month Verta released my first major feature to our platform - the Verta Model Catalog. In this blog post I’ll dive deep into why we built this new offering and how it works. If you’d like to experience Model Catalog for yourself, reach out to us to discuss trial access — or apply to become a Design Partner.
What is Model Catalog?
You can think of Model Catalog as a single source of truth and command center for all your organization’s machine learning assets. Most machine learning teams are working with half a dozen vendors to label data, training models on multiple cloud platforms, and have documentation scattered across Confluence, Git and sporadically published papers — it’s a beautiful mess.
But when it comes to the machine learning models actually in production, all this chaos creates downstream issues for other departments and inevitably slows everyone down, including the ML team:
- The model’s endpoint and schema aren’t clearly documented, so engineers are nagging their product managers to “put that stuff in a ticket.”
- The PMs turn around and shoulder tap the ML engineer or data scientist.
- The finance or risk officer asks the head of ML if the data governance and ML risk evaluation process was followed — and it turns out half the team didn’t even know that process existed.
- Users start getting posts flagged as inappropriate for no reason, so customer support compiles 20 ways the moderation model is messing up - but they don’t know where to send the complaint.
- And so on.
Model Catalog was designed to bring order to this chaos. What does that mean? The data or machine learning scientists who create the model can publish all the relevant information about the model into the catalog via our Python client in their Jupyter notebook. Documentation about the model, methods to reproduce it, its status against production checklists, etc. — all this information is consolidated and organized in Model Catalog automatically and in a way that’s accessible to the entire organization.
How does it work?
Data and Machine Learning scientists register models and metadata about them into the Verta platform — something they’re doing anyway if they’re using Verta to track experiments and deploy and monitor models.
All registered models appear in the catalog for the organization:

Anyone with access can browse, discover and find the right models. Product Managers might want to see which models could be reused in other parts of the organization. DevOps can quickly find the models with live deployments. And new team members can easily get up to speed on models in any domain.
Your team can organize the models any way you see fit. Out of the box, Model Catalog lets you filter models by their machine learning task, the data domain they act on, the owner of the model, when it was last updated, and more. You also can use labels to customize your filters however you want — search through models or sort them to find the one you’re looking for, or discover models you didn’t even know about.

Once you’re in a model, you get key information about it right away through an automatically generated Model Card for the model that stays up to date as new versions are registered. The model’s input and output are clearly visible (whether one feature or 400). Track the model’s progress to production with visibility into which versions are in production now and how many are being developed and tested, and use a “quick link” to learn more about the different versions.
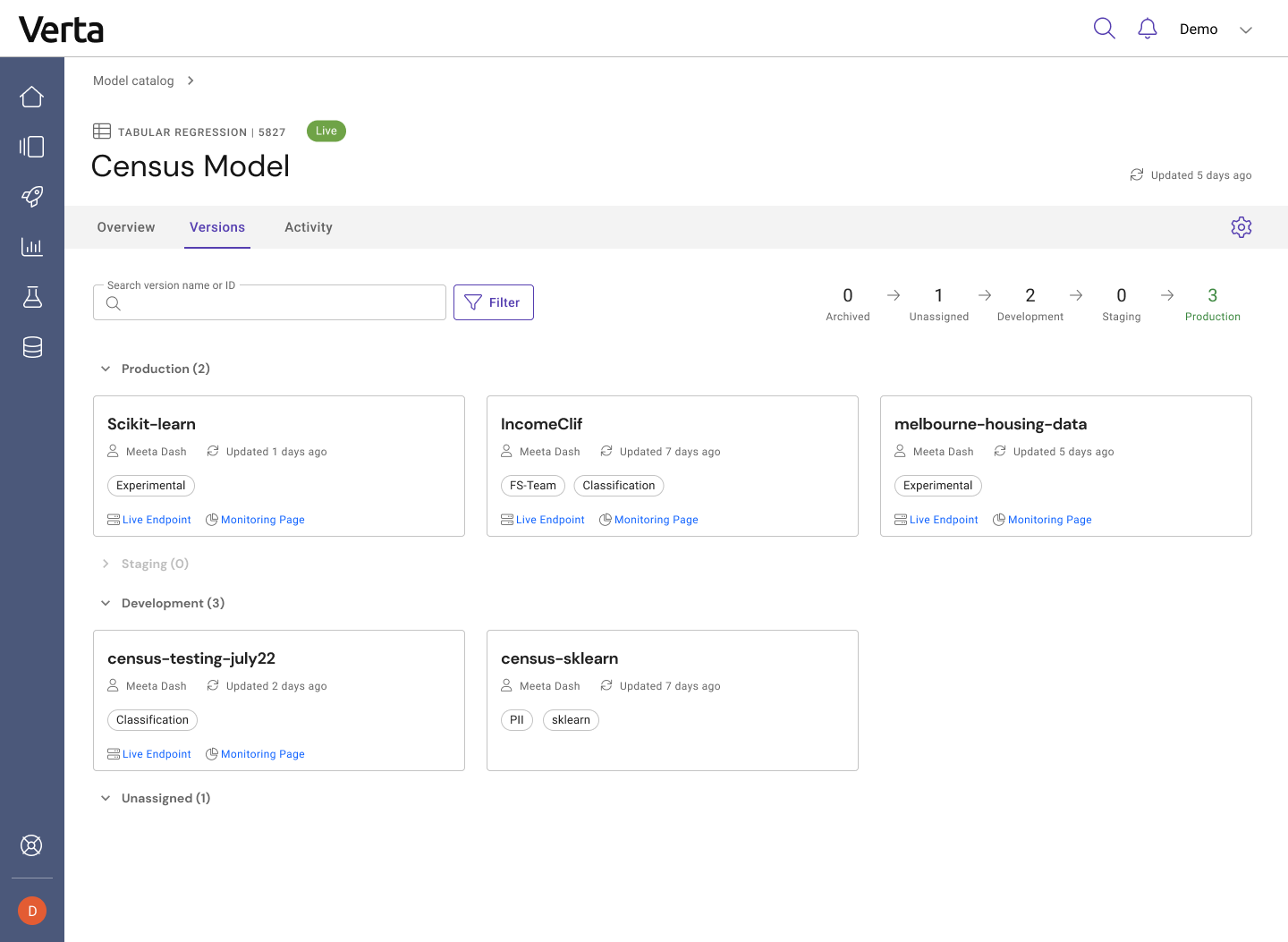
In fact, because tracking model versions is so important, the Versions tab in Model Catalog gives everyone insight into what’s in production now and what’s on deck. You’ll often have just one model version in production at any given time, but two, five, or even 10+ candidates to replace it in various stages of development. Track progress and updates in this tab, and get quick links to the endpoints where these candidates are deployed and to the monitoring dashboards for each of these models. (Next week, I’ll post about what happens when you click on one of these version cards)

For each model, a template is available to write highly robust documentation. The whole team can keep the documentation up to date, just like a wiki. The template includes roughly 20 questions that touch on key themes of fairness and regulations, and that set clear expectations for what the model can and can’t do. Of course, you also can drop in a link to your existing Confluence pages here instead, if that’s easier. Either way, everyone who finds this model will have access to up-to-date information about it.
Model versions also have their own “Read Me” file with a shorter change log template to show what is different between different versions.
![]()
Lastly, Model Catalog lets you track all the activity related to a model. Data science team members can quickly understand if a model’s name was recently changed or when the documentation was last updated. Your risk team can do their quarterly or annual audits easily by filtering for key events they are looking for, or they can download the whole log as a CSV to store in case issues arise.
Next: In the next post, I’ll dive deeper into what’s contained in a model version — how you can reproduce, integrate and release models easily with Model Catalog.
Subscribe To Our Blog
Get the latest from Verta delivered directly to you email.


.png)